Ansible’s system for managing configuration of hosts is inventory. The documentation on inventory - both static and dynamic - is a good reference but I’d like to provide further context through example.
First, some background. Configuring systems and applications can be very simple. Particularly if you only have one or two. Then you can check the configuration into version control on a per host basis, and just manage changes as they come. However, when you have applications in the 100s, and hosts in the 1000s, this approach simply does not scale.
So the goal of effective and efficient configuration management becomes similar to writing good code - Don’t Repeat Yourself, break things down into independent modular units and manage versions well.
I like to think of configuration as a layered set of properties that are applied to a host in turn to combine as the eventual result. A production web server will share a number of properties with its preproduction equivalent (location of files to serve, port to listen on, etc.) but will also have properties in common with other production application servers (databases to talk to, subnets to belong to).
In Ansible inventory, such layers can be modelled as groups - that is a production web server might belong to a production group, a web group and possibly a production-web group for those properties that are particularly specific (e.g. what virtual hosts to serve)
While this might start to seem like an inheritance tree, it’s actually a Directed Acyclic Graph (as a group will likely have multiple children - groups or hosts) and can also have multiple parents - so the production-web group could belong to both production and web groups.
An example inventory graph for the instance we’ll build below is
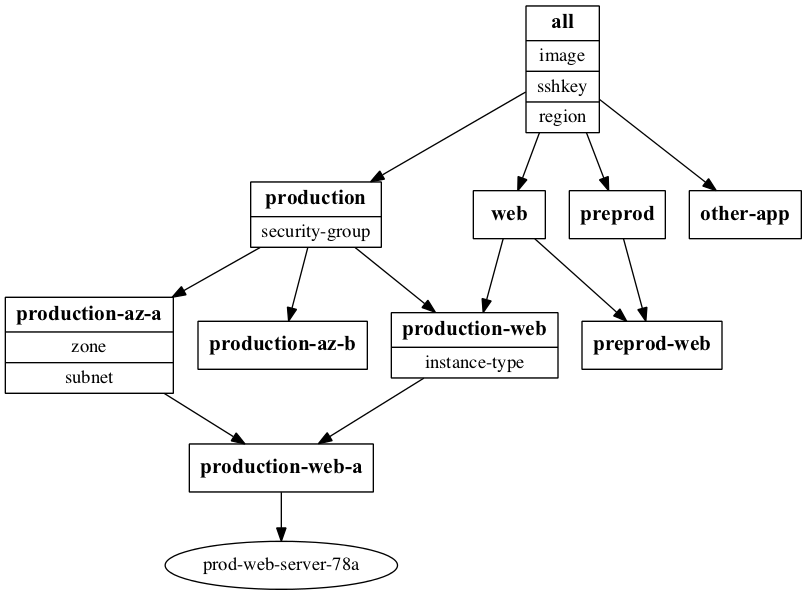
Creating an instance in AWS EC2
This is relatively straightforward, and the ec2 module documentation shows how to do it, but for completeness we’ll describe it here.
A minimal playbook looks like:
---
- hosts: 127.0.0.1
connection: local
tasks:
- name: create ec2 instance with volume that already exists
action:
module: ec2
zone: ap-southeast-2a
image: ami-a1b2c3d4
instance_type: c3.large
state: present
region: ap-southeast-2
vpc_subnet_id: subnet-abcd1234
group: sg-aaaa1111With this in mind then, and bringing this around to AWS, we’ll take the example of an organisation that uses a single AWS region, separate VPCs for preproduction and production.
inventory/group_vars/all.yml
all is a special group that all hosts in inventory, other than localhost, belong to. So this is a great place for site defaults.
region: ap-southeast-2
image: ami-a1b2c3d4
sshkey: YOURKEYNAMEinventory/group_vars/production.yml
security_group: sg-aaaa1111inventory/group_vars/production-web.yml
instance_type: t1.micro(This would be more reasonable instance size in real production but this is an example on the cheap!)
inventory/group_vars/production-az-a.yml
zone: ap-southeast-2a
subnet: subnet-abcd1234inventory/hosts
[production:children]
production-az-a
#production-az-b
production-web
#production-other-app
[web:children]
production-web
#preprod-web
[production-web:children]
production-web-a
#production-web-b
[production-az-a:children]
production-web-a
#production-other-app-a
[production-web-a]
prod-web-server-[1:99]aThe production-web-a group shows a useful way of being able to create instances
in a specific availability zone without needing to know how many of them or their
exact names in advance (I know the Cattle Theory suggests that hostnames are a
thing of the past, but they often convey a lot of inventory information!)
I’ve commented out groups that would lead to other paths along the graph for simplicity’s sake.
create-ec2-instance.yml
---
- hosts: all
connection: local
tasks:
- name: create ec2 instance
action:
module: ec2
zone: "{{ zone }}"
image: "{{ image }}"
instance_type: "{{instance_type}}"
state: present
region: "{{ region }}"
key_name: "{{ sshkey }}"
vpc_subnet_id: "{{ subnet }}"
group: "{{ security_group }}"
instance_tags:
Name: "{{inventory_hostname}}"And then this gets run with:
ansible-playbook -i inventory create-ec2-instance.yml --limit prod-web-server-78a -vvPLAY [all] ********************************************************************
GATHERING FACTS ***************************************************************
<prod-web-server-78a> REMOTE_MODULE setup
ok: [prod-web-server-78a]
TASK: [create ec2 instance] ***************************************************
<prod-web-server-78a> REMOTE_MODULE ec2 region=ap-southeast-2 state=present instance_type=t1.micro vpc_subnet_id=subnet-b3b49fc7 image=ami-5ba83761 zone=ap-southeast-2a group=sg-24bfb446 key_name=YOURKEYNAME
changed: [prod-web-server-78a] => {"changed": true, "instance_ids": ["i-6af51954"], "instances": [{"ami_launch_index": "0", "architecture": "x86_64", "dns_name": "", "hypervisor": "xen", "id": "i-6af51954", "image_id": "ami-5ba83761", "instance_type": "t1.micro", "kernel": "aki-c362fff9", "key_name": "YOURKEYNAME", "launch_time": "2014-03-17T10:31:11.000Z", "placement": "ap-southeast-2a", "private_dns_name": "ip-172-31-20-121.ap-southeast-2.compute.internal", "private_ip": "172.31.20.121", "public_dns_name": "", "public_ip": null, "ramdisk": null, "region": "ap-southeast-2", "root_device_name": "/dev/sda1", "root_device_type": "ebs", "state": "pending", "state_code": 0, "virtualization_type": "paravirtual"}], "tagged_instances": []}
PLAY RECAP ********************************************************************
prod-web-server-78a : ok=2 changed=1 unreachable=0 failed=0 Managing the resulting instance
You can simplify your connections to EC2 instances with something like the following in ~/.ssh/config
Host *.compute.amazonaws.com
User ec2-user
IdentityFile ~/.ssh/YOURKEYNAME.pemManaging the resulting instance can then be through Ansible’s EC2 dynamic inventory For example, using the ec2_facts module to get the EC2 facts about an instance can be as simple as using
EC2_INI_PATH=./ec2.ini ansible-playbook -i ~/src/ansible/plugins/inventory/ec2.py -e instance=prod-web-server-78a ec2-facts.ymlwith the playbook
- hosts: tag_Name_{{instance}}
tasks:
- name: get EC2 facts
action: ec2_factsPLAY [tag_Name_prod-web-server-78a] *******************************************
GATHERING FACTS ***************************************************************
<ec2-54-206-88-224.ap-southeast-2.compute.amazonaws.com> REMOTE_MODULE setup
ok: [ec2-54-206-88-224.ap-southeast-2.compute.amazonaws.com]
TASK: [get EC2 facts] *********************************************************
<ec2-54-206-88-224.ap-southeast-2.compute.amazonaws.com> REMOTE_MODULE ec2_facts
ok: [ec2-54-206-88-224.ap-southeast-2.compute.amazonaws.com] => {"ansible_facts": {"ansible_ec2_ami-id": "ami-5ba83761", "ansible_ec2_ami-launch-index": "0", "ansible_ec2_ami-manifest-path": "(unknown)", "ansible_ec2_ami_id": "ami-5ba83761", "ansible_ec2_ami_launch_index": "0", "ansible_ec2_ami_manifest_path": "(unknown)", "ansible_ec2_block-device-mapping-ami": "/dev/sda1", "ansible_ec2_block-device-mapping-root": "/dev/sda1", "ansible_ec2_block_device_mapping_ami": "/dev/sda1", ...The source code for the inventory and playbooks is also on Github